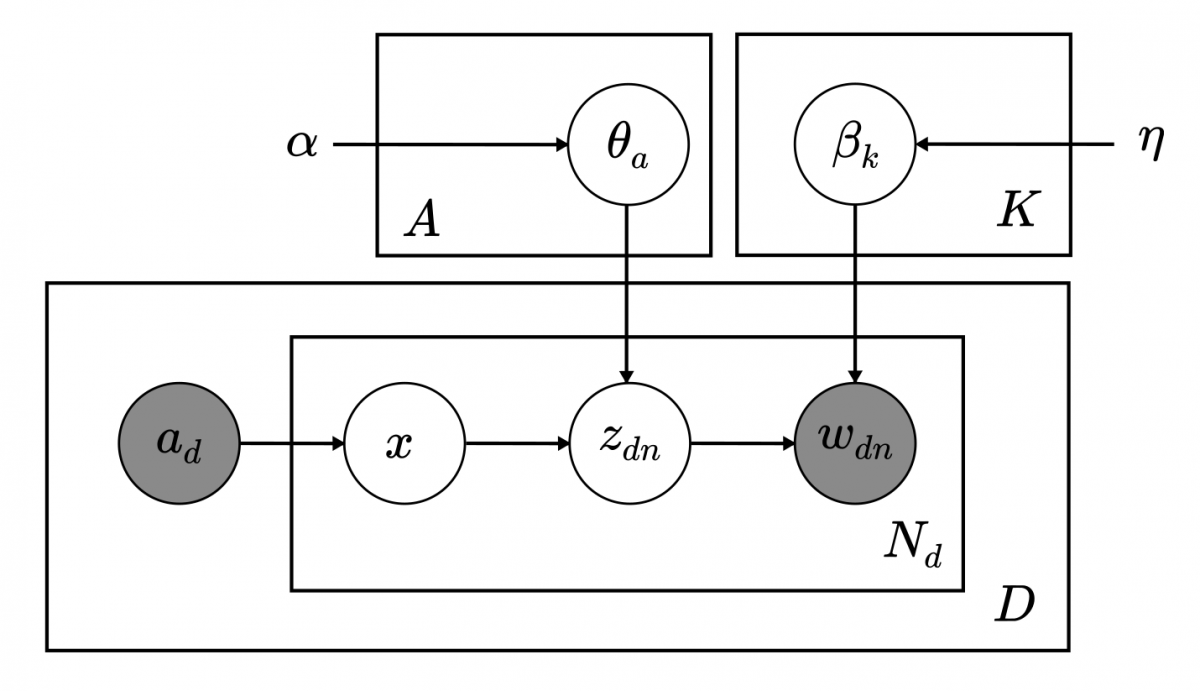
Gensim(ジェンシム)は、最新の統計的機械学習を使用した、教師なしトピックモデリングと自然言語処理のためのオープンソースライブラリである。
Gensimは、Python言語と性能向上を図るためにCython言語で記述されている。Gensimは、データストリーミングとインクリメンタルオンラインアルゴリズムを使用して大規模なテキストコレクションを処理するように設計されており、インメモリ処理のみを対象とした他の多くの機械学習ソフトウェアパッケージとの差別化を図っている。
主な機能
Gensimには、fastText、word2vec、doc2vecアルゴリズムのストリーミング並列化実装に加えて、潜在意味解析(LSA、LSI、SVD)、非負行列分解(NMF)、潜在ディリクレ配分(LDA)、tf-idf、およびランダム射影が含まれている。
Gensimの新しいオンラインアルゴリズムのいくつかは、Gensimの制作者であるRadim Řehůřekの2011年の博士論文『Scalability of Semantic Analysis in Natural Language Processing(自然言語処理における意味解析のスケーラビリティ)』にも掲載されている。
Gensimの使用例
Gensimは、2018年の時点で、医学から保険金請求分析、特許検索まで、さまざまな分野で1,400件を超える商用および学術用途で使用および引用されている。このソフトウェアは、いくつかの新しい記事、ポッドキャスト、インタビューでも取り上げられている。
無償および有償サポート
Gensimのソースコードは、GitHubで開発および公開されており、Google GroupsとGitter上でサポートフォーラムが公開・維持されている。
Gensimは、rare-technologies.com社によって商業的にサポートされている。学生インキュベータープログラムを通じて Gensimの学生メンターシップと学術論文プロジェクトも提供している。
脚注
外部リンク
- 公式ウェブサイト